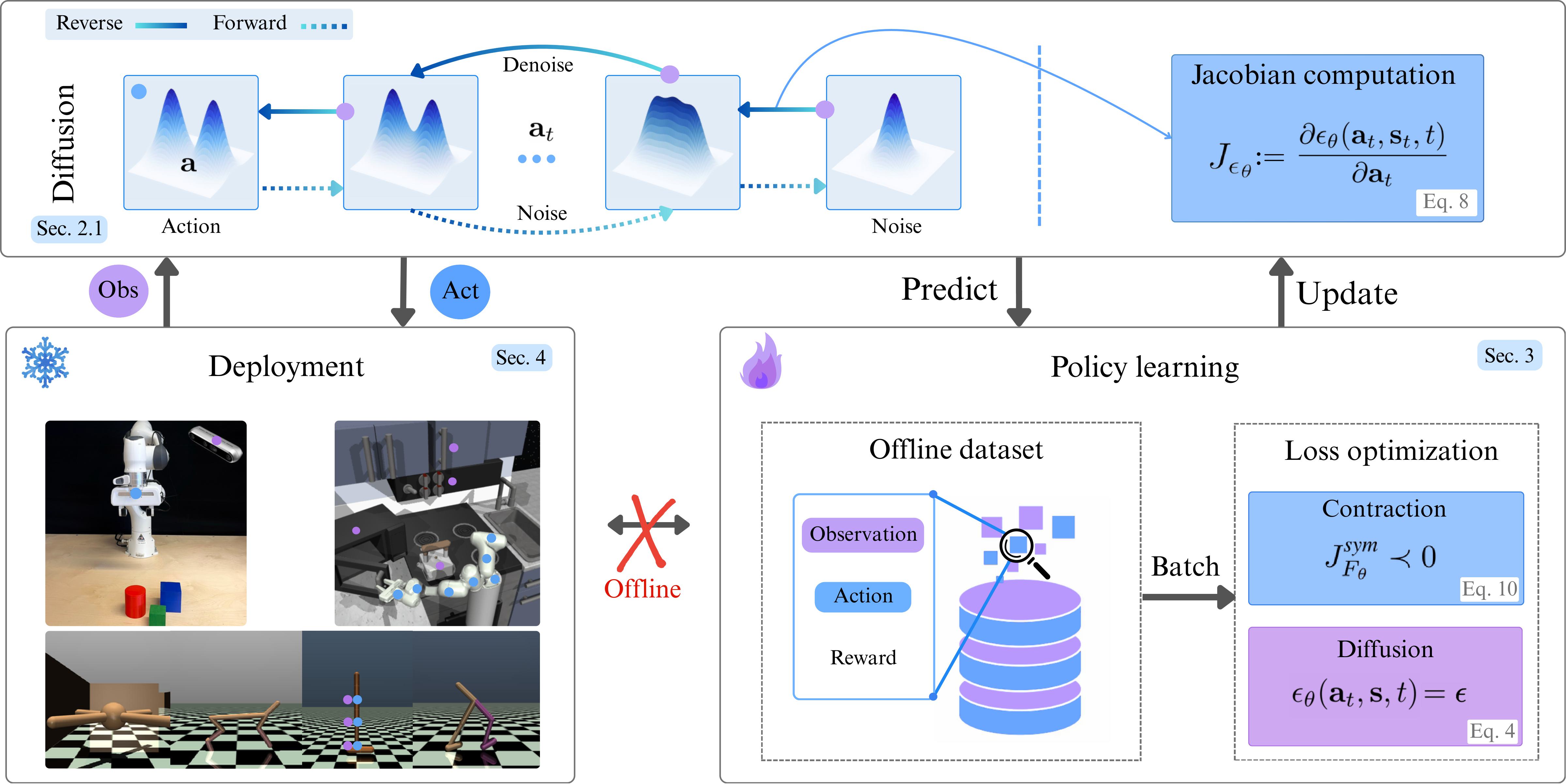
Contractive Diffusion Policies: Robust Action Diffusion via Contractive Score-Based Sampling with Differential Equations
CDPs add a simple contraction regularizer to diffusion policies, pulling nearby sampling trajectories together to suppress solver and score-matching errors. This yields more robust action generation in offline RL and imitation learning, especially in low-data regimes.